As mentioned in AI Sloppiness, lately I’ve been experimenting with and learning about using Stable Diffusion AI to generate images from text prompts.
I thought about doing posts to examine the mechanics behind how Stable Diffusion is able to generate images, as I think it is fascinating. But again, I could not do as well as 3Blue1Brown, with the excellent But how do AI images and videos actually work? video. With this post, I thought I’d focus instead on user-level, real-world, goal-directed usage of AI text-to-image image generators – using AI to generate a certain image that you have in mind for a specific purpose. You don’t have to understand the details of how it works to use AI image generation effectively.
Motivation
We decided to add an image to each post here at Retired Thinker. I’m no artist so I cannot produce the images by conventional means, and I’m not patient enough to sift through public-domain images to find the right free image, so I turned to AI. Many of the images used with posts here were generated at SocialBU. The whole ‘mission’ of that web page is to generate images that are appropriate to go along with blog posts. I like the kitschy, cheerful, don’t-take-yourself-too-seriously cartoon images that it is able to produce. And it understands the prompts that I give it well enough that I am able to get reasonable results with little effort or frustration on my part.
But after a few days of allowing me to generate as many images as I liked, SocialBU started limiting me to two generation attempts per day unless I paid money, which isn’t unreasonable. But, true to my Cheapskating principles, I did not want to spend any additional money to generate post images. I also worried that SocialBU would somehow disappear or change out from underneath me. So I undertook a project to find alternatives for generating post images on the cheap.
Since I thought I’d write a post on Retired Thinker about my post image generation project (i.e. this post), I thought I’d focus the project on generating an image appropriate for use with this post. Confused yet? Because this is a bit self-referential, I wanted the post image to convey the idea of using AI to generate an image that shows a robot (representing AI) drawing or painting an image that shows the same robot creating an image, and that image shows the robot creating an image of the same robot creating an image… on and on recursively. I used the prompt:
The image generator at SocialBU basically ‘one-shotted’ (slang in the AI community for generating something acceptable on the first attempt) an image that I considered usable:

I tried some other online image generators that I had easy access to. I am sure there are hundreds of other image generators out there, but most of them want something from me – money or personal information or both. Here are a few that I tried:
Microsoft Designer was a pleasant surprise, as I haven’t had good experiences with Microsoft’s other AI offerings thus far1. It generated very good images given the same prompt, in fact it generated the image that I deemed to be best and used as the feature image for this post. Microsoft Designer is pretty quick, and gives you 4 ’takes’ on the prompt at once for one ‘credit’. My Microsoft 365 subscription unfortunately has a quota of 20 credits per month. Here is the post featured image and another contender that was produced by Microsoft Designer:


Apple Image Playground on macOS, using Apple’s models: total fail.
ChatGPT also produced images that showed that it ‘got it’, e.g.

Bringing it Home
Because I liked the idea of having a stable, unlimited, and free source of post images, I thought that I’d try setting up my home system to use Stable Diffusion-based AI image generators locally to do the job, using the same prompt. Based on the success I had with online image generators without much effort, I was optimistic that home image generation would be able to handle it just fine.
First some ground rules and constraints for my home image generation project:
I only have a mid-range Nvidia graphics card that is two generations back from the latest, with only 10 GB of VRAM.2 So I would not be able to run the latest, greatest models locally.
Because local image generation involves a lot of software and files downloaded from websites that I don’t necessarily trust, I decided that I wanted the extra safety of running the AI image generation inside a Docker container. This may have added complications and cost me some performance, but the extra peace-of-mind was worth it to me.
There are both open-source (free) and proprietary commercial image generation models available. I only used free open-source models.
The Basics
The basic, top-level overview of how to generate images at home, assuming you have capable hardware:
-
Install some software that implements the Stable Diffusion engine that will execute the AI models and produce the images. This software will present a UI to the user to control the image generation. The most popular choices for this software are Automatic1111 and ComfyUI. I tried both, but I found that I liked ComfyUI better personally. Because I didn’t want to install this software natively on my system, I found and downloaded Docker images that contained either Automatic1111 or ComfyUI.
-
Download AI models to run in the engine. The AI models are data files, usually with a
.safetensorsor.ggufextension, that contain the connection weights for the model neural network(s). Automatic1111 and ComfyUI can load these model files and execute the neural networks to create the images - in some sense these apps are the ‘operating systems’ that run the ‘applications’ that are the AI models. The most popular places to obtain the models are CivitAI and Hugging Face. You will need a base model and perhaps some ‘modifier’ models (LoRAs, ControlNets, VAEs) for those base models that customize the image generation in various ways. There is much complexity glossed over in this step. There are several popular base model families that come in generations, like SD 1.x, SDXL, SD 3.x, Flux, etc. Those base models have spawned many thousands of variants, fine-tuned and merged with other models to supposedly improve generation of certain flavors of images. Honestly, it is a bit overwhelming to choose which models might be worth downloading and running. And while Automatic1111 and ComfyUI have hidden away much complexity by being able to transparently run any of the base model families mentioned above (even though the models’ internal architectures are quite different), you will need to be aware of the model families and generations when it comes to downloading and using the modifiers mentioned above, as those are specific to a base model family. -
Point the Stable Diffusion software at the AI model that you downloaded, set some parameters that control the image generation, enter your prompts3, and press the Run button. On my system, it takes somewhere between 15 seconds and 10 minutes to generate an image, depending mostly on the model size and complexity.
-
Spend hours tweaking the prompts (and to a lesser degree other settings) to try to coax the model to create acceptable images. Press the Run button many, many times. Note that the batch generation features in Automatic1111 and ComfyUI can be your friend.
-
Decide that you got unlucky and downloaded a brain-dead model that can’t follow simple instructions, go choose another model, download it, goto step 3. Lather, rinse, repeat until you need to stop for the day.
ComfyUI and Early Attempts
After starting out with Automatic1111, I switched to using ComfyUI for image generation. In ComfyUI you build workflows that are a graph of nodes wired together. The nodes each perform some function, and contain UI elements to enter any parameters relevant to that function, so the graph of nodes serves both as a ‘program’ for how the image generation will proceed, and as a UI to enter input parameters to the program. There are many different kinds of nodes, some load models, some provide input boxes to enter prompts, some process prompts by adding additional, canned keywords (sometimes called ‘Styles’), etc. An important node is the KSampler node which actually runs the image generation, it has UI to enter inputs like the random seed number and the number of image generation steps to perform. At the end of the workflow is a node that displays the generated image. Here is a screenshot of ComfyUI showing a simple workflow that shows what the image generator produced for an early run using the original prompt:
The ComfyUI interface with an early attempt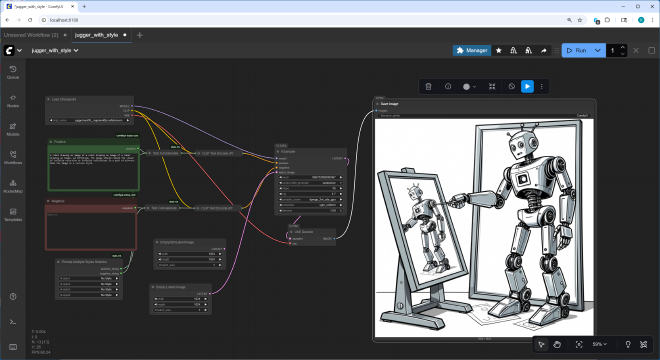
Once you get the hang of it, I think ComfyUI leads to a better understanding of just what is going on during the image generation. The UI is arguably overkill for the simple things I have been doing, but is incredibly flexible and expandable - workflows can be set up to do things far beyond text-to-image generation. And, you needn’t build up workflows from scratch - there are many pre-built workflows and custom ComfyUI nodes available for download. I recommend the ComfyUI Tutorial Series on YouTube that describes in great detail how to set up and use ComfyUI. Honestly, I only watched about the first 10 videos in the series; after that it went into aspects of image generation that were not my primary focus for this project.
Note that the image generated in the above screenshot is rather poor, and that was the best one I saw after generating a significant number of images with this setup. The model just did not grok the recursive image-within-an-image aspect of what I wanted.
Somewhat to my surprise, I found that altering the parameters and prompt (e.g. by including phrases like ‘infinite regress’) and adding negative prompts didn’t really change the fact that the AI model just didn’t grasp the recursive essence of the image that I wanted. Even more to my surprise, I tried many other models, and although some were larger and took significantly longer to generate, none of them picked up on the recursive aspect, and none of them produced images that I considered to be usable for my specific purpose.
Models Prompting Models…
After spending several days trying to tweak prompts with different AI models, I tried a new angle. ChatGPT (among others) has the ability to analyze an uploaded image and from that generate a text prompt suitable for use in an image generator to have it reproduce that image.4 I uploaded the feature image for this post (the one produced online by Microsoft Designer) to ChatGPT and gave it the prompt:
5 It came back with:
“A whimsical cartoon-style scene of a cute retro robot standing upright on two legs, drawing on an easel. The robot has a square body, flexible segmented arms and legs, round glowing orange eyes, and three small antennae on its head. On the easel is a large vertical canvas showing the same robot drawing itself, creating a recursive infinite loop of smaller and smaller robots in the painting. Warm, soft, playful lighting with smooth rounded shapes in the background. Bright, colorful, imaginative, high-detail cartoon illustration with clean lines and a fun, lighthearted tone.”
Obviously ChatGPT grokked the recursive aspect I was going for, just from analyzing the image that I gave it. That greatly impressed me. It also captured the tone and feel of the image in words better than I could have done. But alas, the images generated from my home ComfyUI setup using this prompt were again disappointing, regardless of the model that I used. Here is a typical one:

This failure to coax local image generators to give me the recursion that I wanted was hard for me to accept: I really thought that if I could find the right model and use the right magic words in the prompts that I could generate images comparable to what the online image generators gave me. I could not.
Post Mortem
So what happened?
The AI image generator models that are available for download seem to focus either on photorealism, or on generating manga- or anime-style cartoon images. I wanted neither. I only found a few models that even mentioned being specialized for “Western”-style cartoon images, and those were also terrible at my task.
I thought perhaps I could get better results if I dropped the part about making cartoon-style images and instead had it generate photorealistic images. This helped, giving me better images like this one:

Eventually I asked ChatGPT why I was having such a difficult time generating images that showed recursion, even using the prompt that ChatGPT itself generated for me. It said:
“The issue is that Stable Diffusion (even SDXL) often struggles with recursive or mirror-based scenes, because those require both compositional reasoning and explicit understanding of reflections — something diffusion models don’t handle natively unless carefully guided.”
I guess it is good to know that the technical cards may have been stacked against my effort. But I’m not sure about the ‘carefully guided’ part - I couldn’t get reasonable images even after ‘carefully guiding’ it every which way I could imagine.
Since it never seemed to get the concept, I tried dropping the recursive angle, and just asked for a photorealistic robot painting a self-portrait. This generated better images, e.g.

Despite seeing little difference between the smaller and larger AI models that I tried running locally, I have to conclude that the online models that succeeded at my image generation task are just larger, more sophisticated models that are better at prompt understanding and adherence than the models that I could run at home. And this was made possible because the online models are probably running on more advanced hardware than I have available at home. In the case of SocialBU, they likely have successfully fine-tuned their model to consistently give quality images in a certain cartoon style, and they probably started with an underlying base model sophisticated enough to understand recursion.
I could have tried fine-tuning some existing AI model to produce the kind of images that I wanted. Sites like CivitAI and Hugging Face are filled with AI models that have been fine-tuned towards various purposes (none of those purposes being to generate G-rated blog post image cartoons, unfortunately). Fine-tuning a model requires many sample images that show what you want, and the images each need to be tagged with descriptive text. I thought about using the other post images on Retired Thinker as inputs to fine-tune an AI to generate images more consistent with those already on the site. This may have helped to generate more stylistically similar images, but would not have made the AI suddenly understand the concept of recursion. Plus, using images generated by one AI to train another AI may be in a legal grey area.
When Life Gives You Lemons…
After I became frustrated with trying to get my Stable Diffusion setup to generate the post image that I was after locally, I decided to try to generate photorealistic images that don’t involve recursion, hoping to play more to the strengths of the AI models. I’m glad I did, because I could locally generate some images that impressed me instead of just frustrating me. Here are a few images that are photorealistic AI renditions of the cartoon images used for some other posts on Retired Thinker, can you spot which ones? :) 6



Then I went even further afield and just played with generating images of whatever popped into my mind, again sticking with more ‘mainstream’ areas that the image generator models were built to handle. Here is a random assortment, included only to show what local image generation can do in general.



Summary
I have to say that this project caused more frustration than most. I had to set it aside then come back to it several times. But the journey was interesting.
For local image generation, there is a strange dichotomy: the local image generator models I tried were able to generate excellent images that amazed me when I didn’t really have a goal in mind other than making it produce non-specific cool images. But OTOH, it just completely failed, again and again, to give me a particular image that I wanted for this post. I think getting a good image out of AI is just a matter of getting a lucky seed combined with choosing to generate an image that is aligned with the model’s strengths.
I only scratched the surface with AI image generation - there are vast realms and sub-realms to explore in this general area, if you have the hardware and patience for it. There is a vibrant online community who seem to have made AI image generation their full-time jobs. And as with most things related to AI, it is evolving incredibly quickly - what was cutting-edge yesterday is obsolete today.
After I gave up on getting my goal image locally, I did have some fun with generating images at home. I have never been much of a photographer (at all), but I can sort of see how generating AI images might have a similar underlying appeal - trying to capture an interesting image, but now you just refine prompts and press a Run button many times instead of trying different angles/lighting conditions/framings/shutter speeds/whatever it is that photographers do…
If I do more with home image generation, it might make for a good excuse to upgrade my main Windows machine hardware to the newest generation GPU, which would greatly improve my ability to generate AI images (and probably even movies!) quickly. I’m always looking for reasons to justify my next tech purchase to myself.
-
I was disappointed with the quality of the Copilot AI built in to the Microsoft Office apps. Worse, it was added in such a way that it could not be ignored - in OneNote it put a big intrusive Copilot logo right next to the cursor, and you could not turn it off. When I saw an option to renew my Microsoft 365 subscription without AI, for $30 cheaper than the with-AI option, I jumped on it. The annoying logo next to my cursor went away! Win! I should say though that I have been fairly impressed with the GitHub Copilot that can be used from VS Code, that is completely separate from the Copilot associated with Windows and Office. ↩︎
-
VRAM (Video RAM) is memory on the video card itself that the GPU can access efficiently. Fitting an AI model entirely in VRAM is crucial to getting good AI performance. ↩︎
-
Yes, prompts plural: some models support both a positive prompt for things that you want to see in the image, and a negative prompt listing things that you don’t want to see in the image. ↩︎
-
This is referred to as img-to-txt. What I have been exploring is txt-to-img. Most of the models that I have been trying are also capable of doing img-to-img, where you give it an input image and prompt the AI to alter the image or remake it in a different style. ↩︎
-
Of the many models that I tried, one called “juggernautXL_ragnarok” stood out because it was able to generate images of quality on par with larger models, but it did so much quicker, taking about 15-30 seconds on my system. I learned later that this model was trained on a large amount of NSFW (Not Safe For Work) images. This website recommends adding “NSFW” as a negative prompt to avoid eye-popping surprises in the generated images. Had I known the provenance of this model beforehand, I would not have downloaded it. But I’m glad that I did, because the model apparently retained the ability to generate quality images that would be rated G or PG. A model called “flux1-schnell-fp8” also gets honorable mention. ↩︎
-
These images were again made by txt-to-img with prompts that I recreated to describe the existing post feature image. I could have tried img-to-img, as some AI image generators claim to be able to de-cartoonize images and convert them into photorealistic images. Maybe later. The images are for posts Lazy Physics, Coding for (Social) Security, and Keeping Pace with Progress. ↩︎
