From the title, you might think that this is a post about the sloppy mistakes that AI can make. Or maybe you are more up on jargon and know that “AI slop” can refer to low-quality AI-generated content that floods the internet.
But this post is not about either of those things. Well, not directly. This is a post about quantization.
Model Quantization
Quantization is a procedure that starts with a trained neural network model and reduces the precision of its connection weights (and therefore its memory footprint and computational requirements), without totally destroying the model’s ability to “think”.
Big-league pre-trained LLMs have billions of connection weights that are 32-bit floating-point numbers. Quantization just replaces these connection weights with lower-precision numbers, usually integers, using various ways of mapping the values.
It also provides a savings in computation speed. For example, replacing 32-bit floating-point numbers with 8-bit integers reduces the model memory by 75%. Integer math is faster than floating-point math, resulting in faster evaluation of the neural network.
Incidentally, because evaluating neural networks can be done with integer math instead of floating-point math, the Neural Processing Units (NPUs) that are starting to appear in PCs are rated in TOPS (trillions of operations per second) and not in TFLOPS (trillions of floating-point operations per second).
Amazingly, trained neural network models can be quantized down to 8-bit, 4-bit or even 2-bit (!) integer values without making the model completely brain-dead. Ponder this for a moment. Everything that a neural network is, and everything it can do, is stored in its connections weights. One might be forgiven for thinking that precision here would be important - that a neural network needs to be able to make fine distinctions down to the 7th decimal place (the approximate precision of 32-bit floats) between different connection weight values to encode the subtle differences and nuances of meaning that neural networks can seemingly understand. But no - the connection weights can be reduced down from approximately 1 billion discrete values (the approximate number of different floating-point numbers between 0.0 and 1.0 that can be losslessly stored in 32-bit floats) to just 16 discrete values (for 4-bit integers), usually with only a modest drop in model performance.
There are many different methods and techniques used to quantize models. The various quantization schemes attempt to balance model perplexity (a measure of performance and accuracy of an LLM) against the amount of space and computation saved by the quantization. This post nicely explains the tradeoffs.
Running LLMs Locally
The fact that quantization works enables an interesting possibility: running LLMs locally on your home computer. Obviously, when you use ChatGPT, Gemini or Claude models, the neural networks of the LLM are running in some cloud server farm on some serious hardware that is probably cooled by a river’s worth of water. Your inputs are uploaded and the model outputs are downloaded to your PC for display, but the calculations take place in the cloud. Since these large models can be quantized down to more manageable sizes, it is quite feasible to download and run pre-trained LLMs locally on your PC, even with modest hardware - e.g., a base MacBook M4 Air or a Windows PC with a GPU that is two generations old.
There are emerging standards for file formats (e.g. GGUF, ckpt, safetensors) that store the trained connection weights for a model. You can go to various websites like Hugging Face that have thousands of different models available for download in these file formats. The different models have been trained and customized to do various things, with various training data sets, and have been quantized in various ways.
The technology is changing fast. Instructions for getting an LLM running locally will likely be obsolete by the time you read this. Instead, I recommend searching for ‘running LLMs locally’. At the time of this writing, one easy way to do this is via Docker Model Runner.
Even as this article is being edited, a new player has entered the field: Transformer Lab.
Open Source Application for Advanced LLM + Diffusion Engineering: interact, train, fine-tune, and evaluate large language models on your own computer.
We will explore this tool in a future article.
If you aren’t familiar with Docker, it can be a pretty useful tool to have in your computing toolbox.
You install Docker itself on your system, it comes with Docker Desktop, which is a reasonable modern GUI interface to Docker functionality.
You can then use it to provide safe ‘sandboxes’ to try out software packages that you might not want to install ’natively’ on your computer. Docker’s purpose is to run containers, which are isolated (sandboxed) environments that have been set up with all the dependencies and settings that the software requires in place. I’ve not had occasion to build containers using Docker, but other fine folks have built Docker containers that I download and use.
When you are finished with the containerized software, just delete the Docker container and it will not leave any trace of that software environment lingering on your system.
About 3 months ago, I used Docker to download and run containers that included an installation of Ollama, along with one or more LLMs. Ollama is basically an engine that runs LLMs on your computer. Recently, Docker has added the Docker Model Runner (still in beta at the time of writing), which makes finding, downloading and running different containerized LLMs even easier than it was before. Once models have been downloaded, which is easily done via the Docker Hub screen, running the LLM locally is just a matter of pressing the play button, and it provides a standard chat interface to the LLM. Just press the trashcan button to get rid of the model when you are through with it.
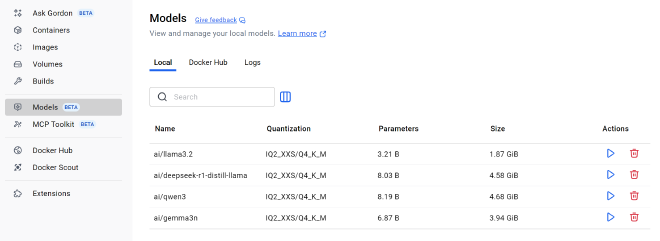
This screenshot from the Docker Model Runner shows a random selection of LLMs that I have downloaded at the moment. Note the Quantization column, which lists a code for how each model has been quantized. The meaning of this “IQ2_XXS/Q4_K_M” code is roughly:
- Part of the model has been quantized with IQ2_XXS and part has been quantized with Q4_K_M
- IQ2_XXS means the weights have been crushed down to a 2-bit (!) integer representation, using a technique called I-quant. The XXS means “extra extra small”.
- Q4_K_M means the weights are 4-bit precision, and the K and M refer to the techniques used to do the mapping down to the quantized values.
Note from the screenshot that quantization allows a model that has 8.03 billion connection weights to only take up 4.58 GB of memory.
I have just noticed that Ollama now offers a similar new app that is a chat-style interface built on top of the Ollama engine. So instead of running LLMs locally inside a Docker container, I could have just installed the new Ollama app to run models locally.
Docker Model Runner and Ollama will take advantage of your Nvidia GPU if you have one (on Windows at least). If a quantized model’s size is reduced sufficiently, the model will fit entirely in the VRAM in your GPU. In my case that’s 10 GB (for a somewhat outdated GPU - modern GPUs can have up to 32 GB of VRAM).
Performance of models that fit in VRAM on a GPU will be much faster than models that do not.
In addition to LLMs, I have also tried running Stable Diffusion-based image generators locally. Frankly I have had less success with this. It was much more difficult to set up, and when I did manage to generate images, they were quite terrible and unusable. I’m not sure if there is a magic “turn down the suck” knob that I haven’t found yet, or I’ve just downloaded really stupid models.
A word of warning should you go down this path: one reason people might want to generate AI images locally is to produce various styles of NSFW images and videos. Many (perhaps most) of the diffuser models that you can find for download have been fine-tuned (a process to be discussed later) to produce these… uh… racy images. You may not want some of these generator models to appear in your download history.
While I’m not doing anything at the moment that requires me to run an LLM or image generator locally instead of just using a more-capable model in the cloud, I find it interesting to run models locally nonetheless. It is somehow satisfying to have my CPU fan kick on and my GPU temperature spike when I ask a local LLM a question, and my computer has to work hard doing scads of matrix multiplications to evaluate the model.
In the Docker Model Runner there is a toggle to enable or disable letting the model use your GPU, so you can see what a huge difference the GPU makes to performance. By downloading different models and basically asking them all the same questions, I saw some tiny models where the perplexity/compression tradeoff was pretty bad - the quantization made these models too stupid and they produced answers that were obviously wrong. But it was still interesting to examine the mistakes that these lobotomized models made - e.g. obvious factual errors but the answer was still worded and presented very well, i.e. ‘hallucinations’. Some were actually quite hilarious.
And, stepping back, it still amazes me that I can download an LLM from the internet in about a minute, run it entirely on the hardware sitting on my desk in front of me (or on my lap), and ask it questions in natural language about topics as diverse as calculus and the casts of movies, and it knows, and answers me in natural language. Somehow downloading and running LLMs locally literally ‘brought it home’ to me, and made LLMs seem more real than just some magic technology running somewhere in the cloud.
Some Deep (Learning) Thoughts
The fact that quantization works means that a ~4 GB download can contain the essence of an LLM that can both understand and produce natural language, AND is knowledgeable enough to answer questions about many different topics. This must be telling us something profound. One thing it is telling us is that neural networks can be ‘sloppy’ - they are not precision machines. The knowledge must be encoded not in the connection weight values themselves, which can be immensely slop-ified via quantization, but instead in the relationships between the connection weights.
To me this goes back to the oft-repeated statement that neural networks function in huge-dimensional spaces of connection weights, and we humans are just beginning to understand what can happen in these spaces. It is apparently OK to greatly reduce the number of possible values along these dimensions via quantization, and it still preserves the essence of the relationships between each dimension and millions of other dimensions that may relate to it in some way.
Summary
As with most things in AI, quantization technology and the ability to run AI models locally is evolving very quickly. New models are appearing daily, and are being quantized using new, smarter methods. As an example, what I have been discussing is known as Post-Training Quantization (PTQ). Another way to achieve quantization is Quantization-Aware Training (QAT), where the quantization is done during the training phase of the large model itself. This makes training even more computationally expensive, but it generally results in small models that are more capable. You can easily find and download models that have used QAT now.
As I mentioned, I downloaded and ran some LLMs locally about three months ago, then I decided to start over today using Docker Model Runner (which didn’t exist three months ago, AFAIK). I was amazed at how far things have come in just that short time. The whole technology to download and run quantized LLMs locally was friendlier, and the quantized LLMs that I played with today seemed noticeably more capable. I should come back to this in another three months to see how much more progress has been made.
